

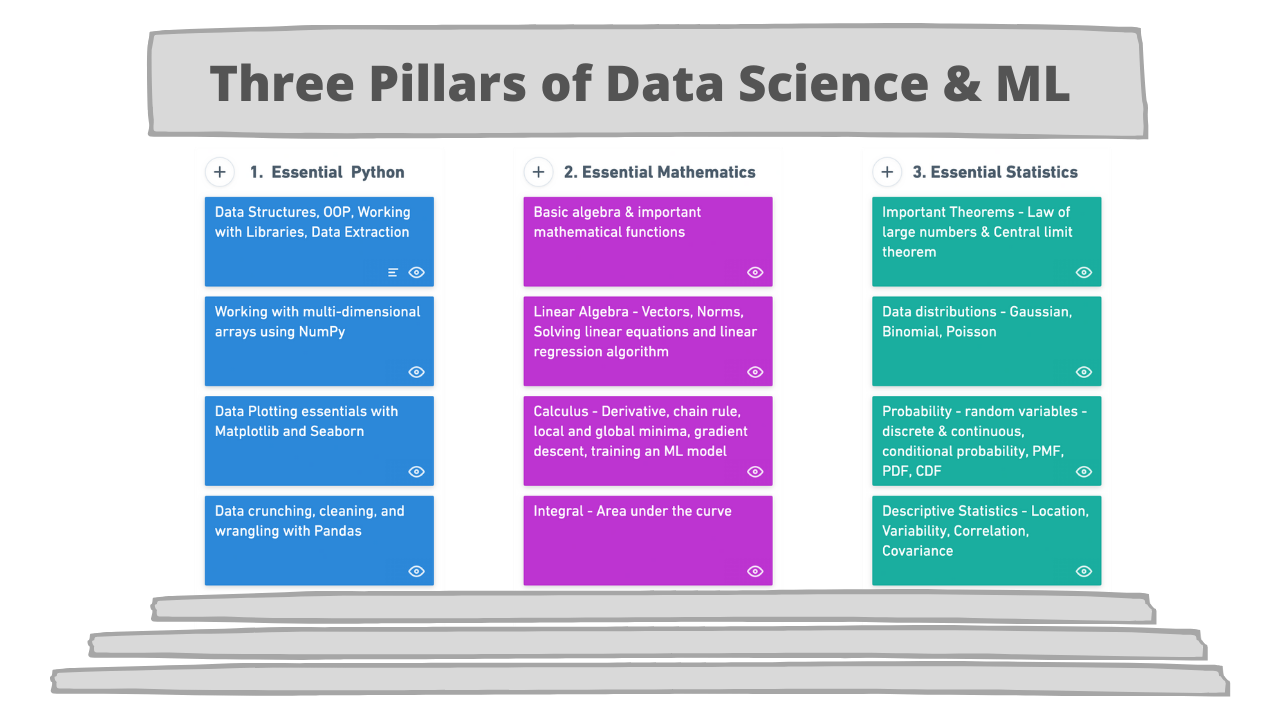
After going through the complete list of concepts and skills that are mentioned in the Google article, I also went through the several books(Deep Learning by Ian Goodfellow, Deep Learning with Python by Francois Chollet, and several others) and I tried to distill the essentials into three branches that are needed to build a solid foundation for a career as a Data Analyst/Scientist/ML Engineer.
Following are the three pillars along with the a list of concepts that are needed to
Programming for complete beginners in Data Science and ML
Programming is telling the machine predefined rules to process input data and then get the results.
Machine learning, on the other hand, is giving the machine the results and data to find the rules that best approximates the relationship between data and the results.
Programming offers that base platform using which you can automate, verify and solve problems of any scale.
The next question is which language should you learn?
Since most of the courses, libraries, and books are written to support Python infrastructure, I recommend learning Python and so does Google’s guide. Which language you use is a personal choice and a lot of it depends on the type of problem you’re trying to solve.
Most beginners prefer Python as it is the best way to develop end-to-end projects and there is a very large community of fellow developers who can help you. Chances are that ~90% of the problems that you’ll encounter in your journey(especially in the beginning phase) are already solved and documented for you.
1. Essential Python Programming for ML
Most data roles are programming-based except for a few like business intelligence, market analysis, product analyst, etc.
I am going to focus on technical data jobs that require expertise in at least one programming language. I personally prefer Python over any other language because of its versatility and ease of learning — hands-down a good pick for developing end-to-end projects.
A glimpse of topics/libraries one must master for data science/ML:
- Common data structures(data types, lists, dictionaries, sets, tuples), writing functions, logic, control flow, searching and sorting algorithms, object-oriented programming, and working with external libraries.
- Writing python scripts to extract, format, and store data into files or back to databases.
- Handling multi-dimensional arrays, indexing, slicing, transposing, broadcasting and pseudorandom number generation using NumPy.
- Performing vectorized operations using scientific computing libraries like NumPy.
- Manipulate data with Pandas — series, dataframe, indexing in a dataframe, comparison operators, merging dataframes, mapping, and applying functions.
- Wrangling data using pandas — checking for null values, imputing it, grouping data, describing it, performing exploratory analysis, etc.
- Data Visualization using Matplotlib — the API hierarchy, adding styles, color, and markers to a plot, knowledge of various plots and when to use them, line plots, bar plots, scatter plots, histograms, boxplots, and seaborn for more advanced plotting.
2. Essential Mathematics
There are practical reasons why Math is essential for folks who want a career as an ML practitioner, Data Scientist, or Deep Learning Engineer.
2.1 Linear algebra to represent data
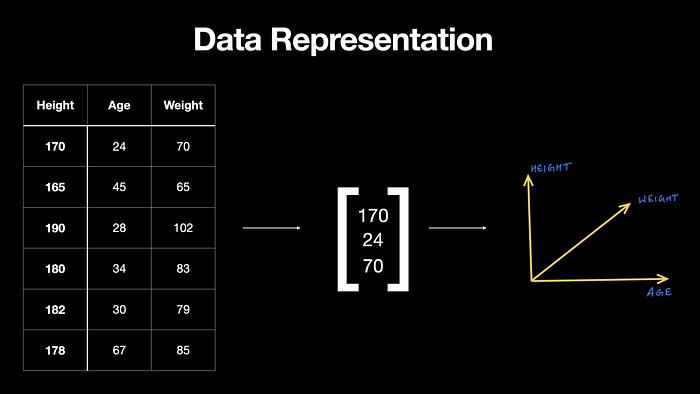
ML is inherently data-driven; data is at the heart of machine learning. We can think of data as vectors — an object that adheres to arithmetic rules. This leads us to understand how rules of linear algebra operate over arrays of data.
2.2 Calculus to train ML models

If you are under the impression that a model training happens “automatically”, then you are wrong. Calculus is what drives the learning of most ML and DL algorithms.
One of the most commonly used optimization algorithms — gradient descent — is an application of partial derivatives.
A model is a mathematical representation of certain beliefs and assumptions. It is said to learn(approximate) the process(linear, polynomial, etc) of how the data is provided, was generated in the first place and then make predictions based on that learned process.
Important topics include:
- Basic algebra — variables, coefficients, equations, functions — linear, exponential, logarithmic, etc.
- Linear Algebra — scalars, vectors, tensors, Norms(L1 & L2), dot product, types of matrices, linear transformation, representing linear equations in matrix notation, solving linear regression problem using vectors and matrices.
- Calculus — derivatives and limits, derivative rules, chain rule (for backpropagation algorithm), partial derivatives (to compute gradients), the convexity of functions, local/global minima, the math behind a regression model, applied math for training a model from scratch.
3. Essential Statistics for Data Science
Every organisation today is striving to become data-driven. To achieve that, Analysts and Scientists are required to use put data to use in different ways in order to drive decision making.
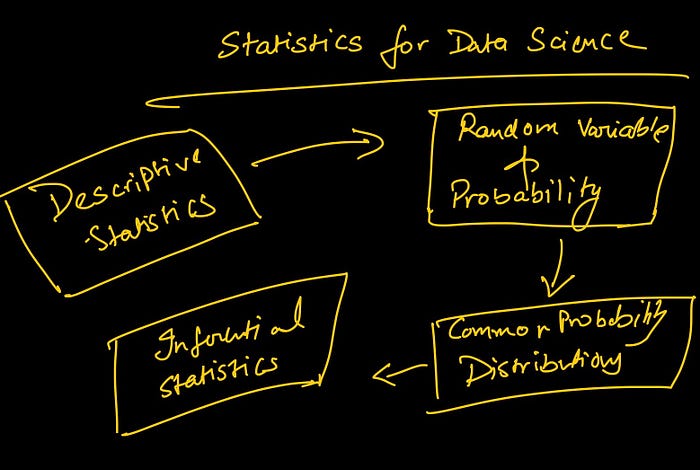
Describing data — from data to insights
Data always comes in raw and ugly. The initial exploration tells you what’s missing, how the data is distributed, and what’s the best way to clean it to meet the end goal.
In order to answer the defined questions, descriptive statistics enables you to transform each observation in your data into insights that make sense.
Quantifying uncertainty
Furthermore, the ability to quantify uncertainty is the most valuable skill that is highly regarded at any data company. Knowing the chances of success in any experiment/decision is very crucial for all businesses.
Here are a few of the main staples of statistics that constitute the bare minimum:
- Estimates of location — mean, median and other variants of these.
- Estimates of variability
- Correlation and covariance
- Random variables — discrete and continuous
- Data distributions — PMF, PDF, CDF
- Conditional probability — bayesian statistics
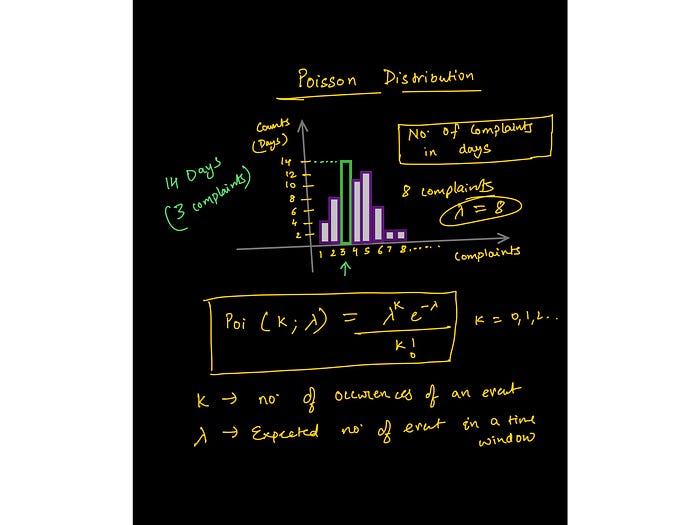
- Commonly used statistical distributions — Gaussian, Binomial, Poisson, Exponential.
- Important theorems — Law of large numbers and Central limit theorem.
ConversionConversion EmoticonEmoticon