

We are going to look at the 20 Python Packages you should know for all your Data Science, Data Engineering, and Machine Learning projects. These are the packages that I found most useful during my career as a Machine Learning Engineer and Python Programmer. While such a list can never be complete, it surely gives you a few tools for every use case.
In case I missed your favorite, be sure to add to the knowledge of others and let them know in the comments down below.
1. Open CV
The open-source computer vision library, Open-CV, is your best friend when it comes to images and videos. It offers great efficient solutions to common image problems such as face detection and object detection. Or, as we can see below, Edge detection, the process of detecting various lines inside an image. If you are planning to work with images in data science, this library is a must. Open CV gathered a massive 56,000 stars on Github and made working with image data several times faster and easier for me.
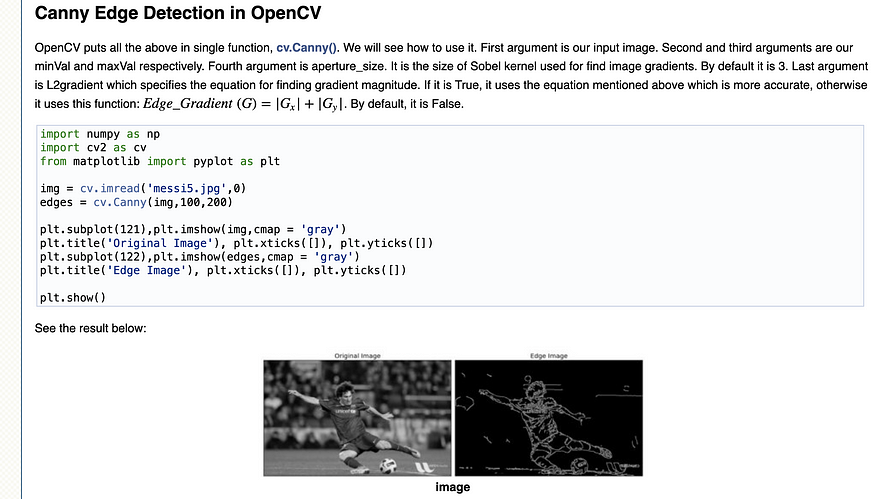
Screenshot from OpenCV.
2. Matplotlib
Data visualization is your main way to communicate with non-Data Wizards. If you think about it, even apps are merely a way to visualize various data interactions behind the scene. Matplolib is the basis of image visualization in Python. From visualizing your edge detection algorithm to looking at distributions in your data, Matplolib is your partner in crime. 14,000 stars on GitHub and surely a great library to start contributing to. I made, for example, this animated lineplot in a recent video using seaborn and matplotlib.

GIF showing the popularity of Programming Languages over time.
3. pip
Given that we are talking about Python packages, we have to take a moment to talk about their master pip. Without it, you can’t install any of the others. Its only purpose is to install packages from the Python Package Index or places such as GitHub. But you can also use it to install your own custom-build packages. 7400 stars just don’t reflect how important it is for the Python Community.
4. Numpy
Python wouldn't be the most popular programming language without Numpy. It is the foundation of all data science and machine learning packages, an essential package for all math-intensive computations with Python. All that nasty linear algebra and fancy math you learned in university are basically handled by Numpy in a very efficient way. Its syntax style can be seen in many of the important data libraries. 18,100 stars on GitHub give you a glimpse into how crucial of a basis for the python ecosystem it is.
5. Pandas
Built mostly on Numpy, it is the heart of all data science you can ever do with Python. “import pandas as pd” is the first line of code I type in the morning, and it is much more than Excel on steroids. Its declared goal is to become the most powerful open source data tool available in any language, and I think they are more than halfway there. While it often is not the fastest tool, there are many sub tools to speed it up, such as Dask, swifter, koalas, and others that build on their syntax and ease of use to make it also useful for big data projects. 30,900 stars on GitHub, truly the starting point for any aspiring data wizard.
6. Python-dateutil
If you ever worked with dates in Python, you know doing it without dateutil is a pain. It can compute given the current date, the next month, or the distance between dates in seconds. And most importantly, it handles the timezone issues for you, which, if you ever tried doing it without a library, can be a massive pain. 1,600 stars on GitHub show you that gladly not many people have to go through the frustrating process of working with timezones.
7. Scikit-Learn
If Machine Learning is your passion, then the Scikit-Learn project has got you covered. The best place to get started and also the first place to look for any algorithm that you could possibly want to use for your predictions. It also features tons of handy evaluation methods and training helpers, such as grid search. Whatever predictions you are trying to get out of your data, sklearn (as it is often aliased) will help you do it more efficiently. 47,000 stars on GitHub tell you why Python is the Machine Learners Language of choice.

Screenshot from Scikit-learn.
8. Scipy
This is kind of confusing, but there is a Scipy library, and there is a Scipy stack. Most of the libraries and packages I wrote about in this article are part of the Scipy stack for scientific computing in Python. This includes Numpy, Matplolib, IPython, and Pandas. Just like Numpy, you most probably won’t use Scipy itself, but the above-mentioned Scikit-Learn library heavily relies on it. Scipy provides the core mathematical methods to do the complex machine learning processes. Again somewhat strange that it has only around 8,500 stars on GitHub.
9. TQDM
If you wonder what my favorite Python package is, look no further. It’s this little application called TQDM. All it really does is that it gives you a processing bar that you can throw around any for loop, and it will give you a progress bar that tells you how long each iteration takes on average, and most importantly, how long it will take such that you know exactly for how long you can watch YouTube videos before you have to go back to work. 19,300 stars for my favorite package, which gave me more peace of mind in the last years than any other package.
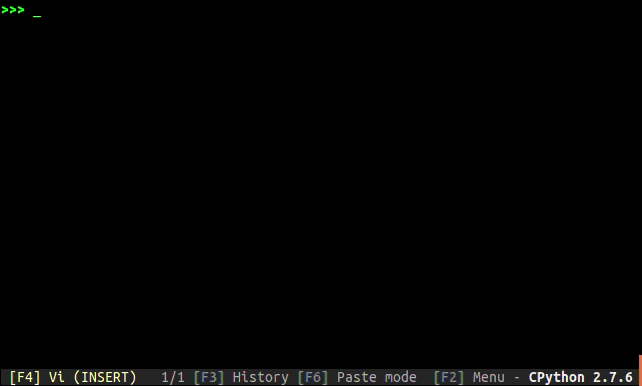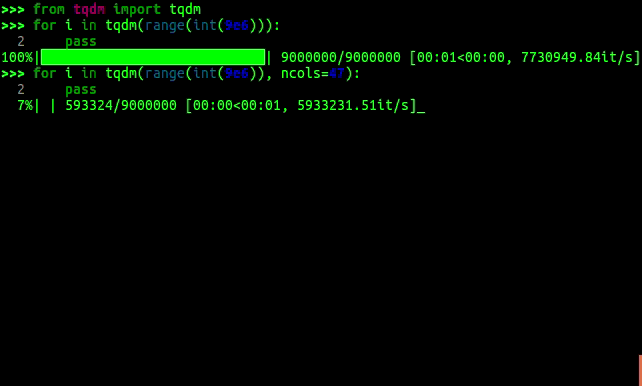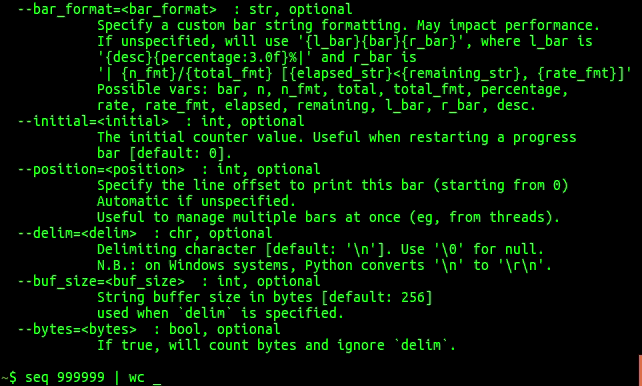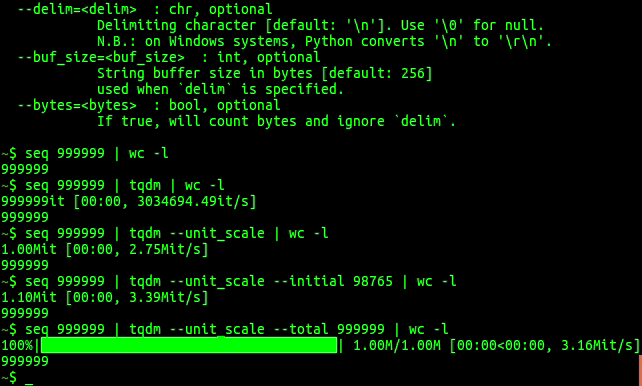
GIF from TQDM-Github.
10. TensorFlow
The most popular Deep Learning framework and really what made Python what it is today. Tensorflow is an entire end-to-end open-source machine learning platform that includes many more packages and tools such as tensorboard, collab, and the What-If tool. Chosen by many of the world-leading companies for their deep learning needs, TensorFlow is, with a staggering 159,000 stars on GitHub, the most popular python package of all time. It is used for various deep learning use cases by companies such as Coca-Cola, Twitter, Intel, and its creator Google.
11. KERAS
A deep learning framework made for humans as their slogan goes. It made rapidly developing new neural networks a thing. I remember before Keras it was quite the effort to write even a simple sequential model. It is based on top of TensorFlow and really the way developers start when they first try around with a new architecture for their model. It reduced the entry barrier for starting to program neural networks by so much that most high school students could do it by now. Keras is another hugely popular Python package at around 52,000 stars.
12. PyTorch
TensorFlow’s main competitor in the deep learning space. It has become a great alternative and my personal favorite for developing neural networks. I think its community is a bit stronger in the realm of natural language processing, while TensorFlow tends to be a bit more on the image and video side. As with Keras, it has its own simplifying library, Pytorch Lightning, which I made an entire tutorial about to make sure you will never again have to work to be good at deep learning. 50,000 stars on GitHub may seem like little compared to Tensorflow, but when looked at over time, it is truly catching up fast.
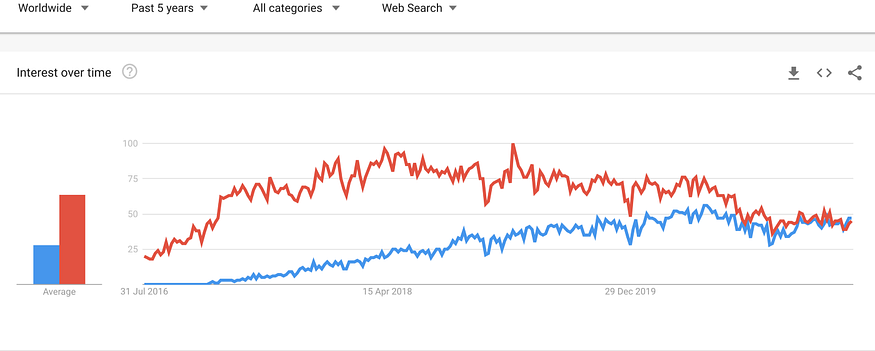
Screenshot from Google Trends, Blu: PyTorch Red: Tensorflow
13. Statsmodels
Statsmodel, in contrast to the fancy new Machine Learning world, is your door to the classical world of statistics. It contains many helpful statistical evaluations and tests. In contrast, these tend to be a lot more stable and surely something any Data Scientist should use every now and then. 6,600 stars are probably more feedback on the coolness of deep learning vs. classical statistics.
14. Plotly
The big alternative to Matplolib is Plotly, objectively more beautiful, and far better for interactive data visualizations. The main difference to Matplolib is that it is browser-based and slightly harder to start with, but once you understand the basics, it is truly an amazing tool. Its strong integration with Jupyter makes me believe that it will become more and more standard and make people move away from Matplolib integrations. 10,000 stars on GitHub and slowly catching up with Matplolib.

Screenshot from the Plotly gallery.
15. NLTK
Short for the Natural Language Toolkit, this is your best friend when you are trying to make sense of any text. It contains extensive algorithms for various grammatical transformations such as stemming and incredible lists of symbols that you might want to remove before processing text in your models, such as dots and stop words. It will also detect what is most likely a sentence and what is not to correct grammatical errors made by the “writers” of your dataset. All in all, give it a shot if you are working with text. Again 10,000 stars, which is crazy for a niche package like this one
16. Scrapy
If you ever tried doing data science without data, I assume you realized that is rather pointless. Luckily the Internet contains information about almost everything. But sometimes, it’s not stored in a nice CSV-like format, and you first have to go out into the wild and gather it. This is exactly where scrapy can help you by making it easy to crawl websites around the globe using a few lines of code. Next time you have an idea where no one pre-gathered the dataset for you. Be sure to check out this 41,000-star project.
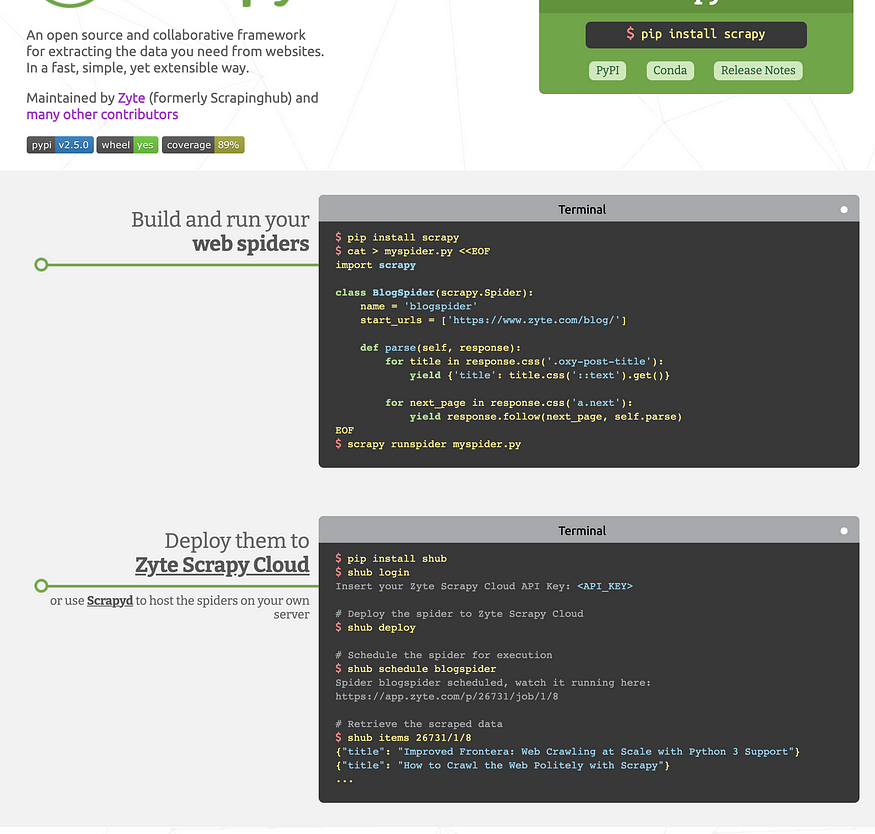
Screenshot from Scrapy.
17. Beautiful Soup
A very similar use case, often these web developers store their data in an inferior data structure called HTML. To make use of that nested craziness, beautiful soup has been created. It helps you extract various aspects of the HTML, such as titles and tags, and lets you iterate them like normal dictionaries. It helped me in several little projects where I was interested in user comments on websites that do not offer an open API.
18. XGBoost
Once our dataset size crosses a certain terabyte threshold, it can be hard to use the common vanilla implementation of Machine Learning algorithms often offered. XGBoost is there to rescue you from waiting weeks for the computations to end. It is a highly scalable and distributed gradient boosting library that will make sure your calculations run as efficiently as possible. Available in almost all common data science languages and stacks.
19. PySpark
Data Engineering is part of every Data Science workflow, and if you ever tried to process billions of data points, you know that your conventional for loop will only get you this far. PySpark is the Python implementation of the very popular Apache Spark data processing engine. It is like pandas but built with distributed computing in mind from the very beginning. If you ever get the feeling that you can't process your data fast enough to keep track, this surely is exactly what you need. They also started focusing on massive parallel Machine Learning for your very big data use cases. 30,000 stars on Github make it one of the most popular data processing tools out there.

Screenshot from Spark.
20. Urllib3
Urllib3 is a powerful, user-friendly HTTP client for Python. If you are trying to do anything with the Internet in Python, this or something that builds on it is a must. API crawlers and connection to various external data sources included. 2,800 stars on GitHub don’t lie.
Conclusion
These have been the 20 most important packages I worked with in my career as a Machine Learning Engineer and Python Programmer. I am sure they will help you in your time of need as you look up a table of possible solutions. Please be sure to comment on your favorite package down below such that others can benefit from your knowledge too.
ConversionConversion EmoticonEmoticon